Home
Infographics
Book
Tools
Tools Directory
DataViz Guides
DataViz Shows
Word Clouds
Sankey Diagrams
Online Infographics Design
Online DataViz
Analytics Platforms
Infographic Resumes
Vector Graphics
Icon Libraries
Color Pickers
Presentation Design
JavaScript Charts
Free Stock Images
Jobs
Posters
Links
Appearances
About
Contact
Follow Cool Infographics
Need Infographics?
Randy Krum
Designer | Author | Instructor | Speaker
FREE Sample Chapter
Read More
All tagged
computer
Aug
9
Aug 9
MacBook Setup Essentials for College Students (2021 UPDATE)
Randy Krum
Apr
21
Apr 21
534 Apple Products On One Giant Poster
Randy Krum
Sep
20
Sep 20
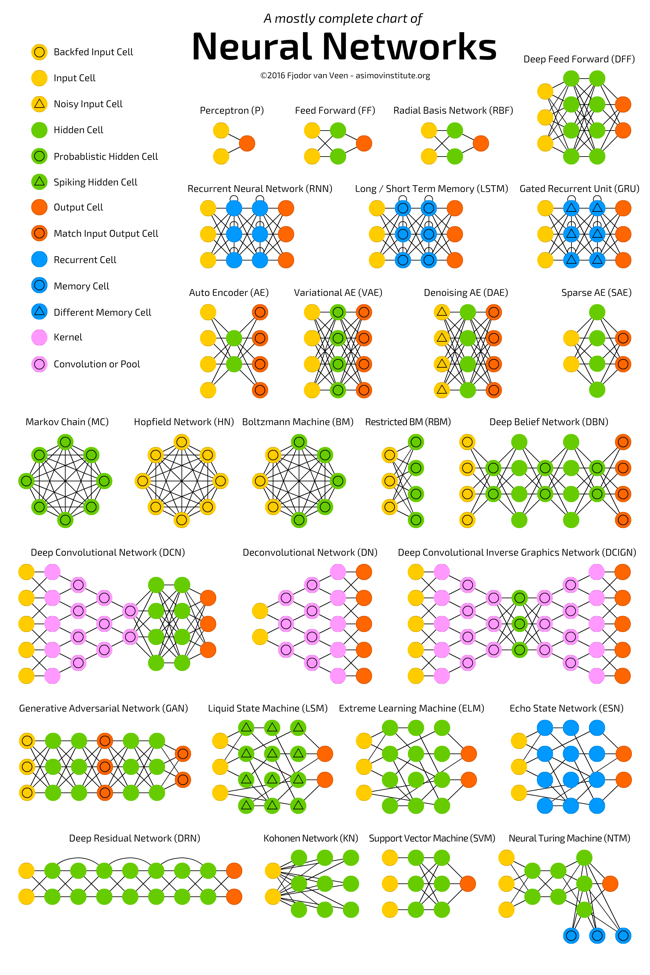
The Mostly Complete Chart of Neural Networks
Randy Krum
Jul
13
Jul 13
A Brief History of Open Source Code
Randy Krum
Apr
12
Apr 12
IT Infirmity: What's Ailing Your IT Department on 2012?
Randy Krum